MMM: Generative Masked Motion Model (CVPR 2024, Highlight)
Ekkasit Pinyoanuntapong°, Pu Wang°, Minwoo Lee°, Chen Chen†
°University of North Carolina at Charlotte, †University of Central Florida
arXiv Code Demo Youtube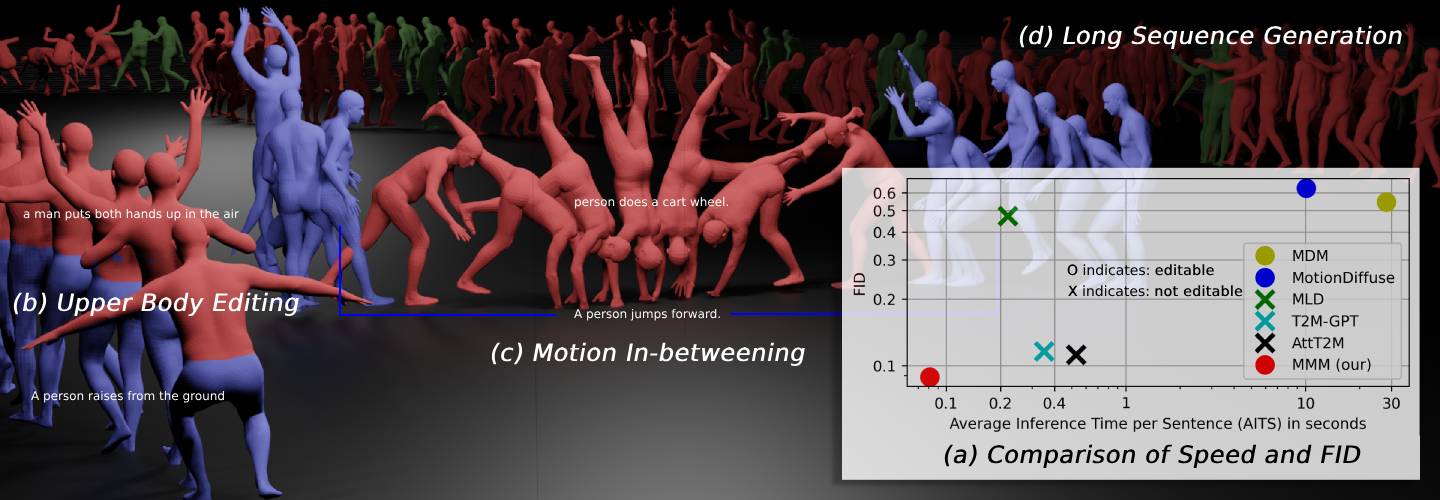
Abstract
Fast, High Quality, and Editable
Comparison of the inference speed and quality of generation on text-to-motion along with the editable capability of each model. "✓" means editable while "✗" is not and "-" refers to has-capability but no application provided. We calculate the Average Inference Time per Sentence (AITS) on the test set of HumanML3D without model or data loading parts. All tests are performed on a single NVIDIA RTX A5000.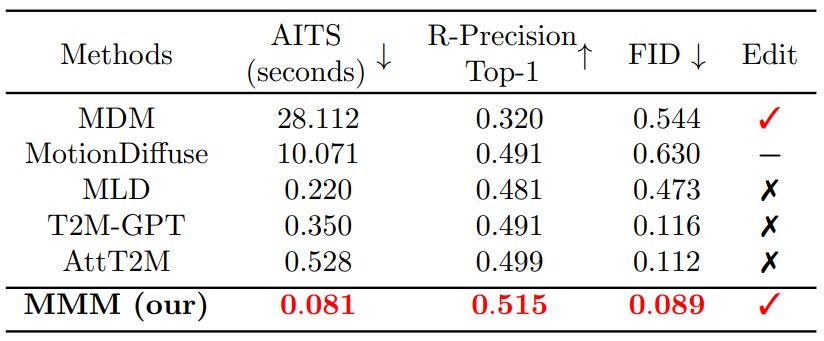
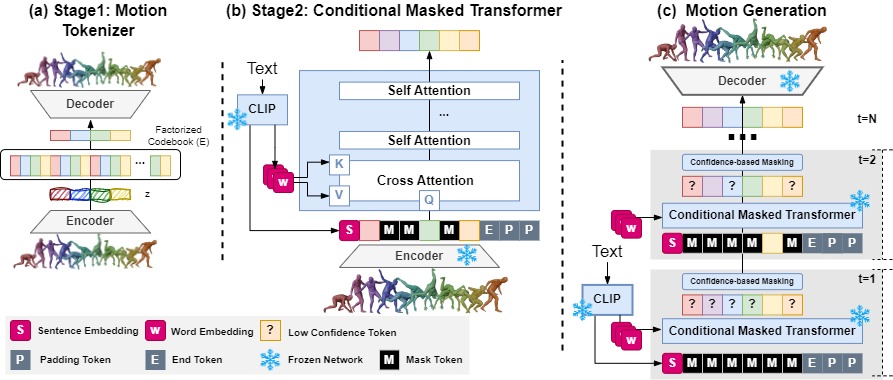
Overall architecture of MMM
Motion Editing
Compared to SOTA
Text to Motion 1:
"a person walks forward then turns completely around and does a cartwheel"
MMM (our)
Ground Truth
T2M-GPT
MLD
MDM
Text to Motion 2:
"a man walks forward, stumbles to the right, and then regains his balance and keeps walking forwards."
MMM (our)
Ground Truth
T2M-GPT
MLD
MDM
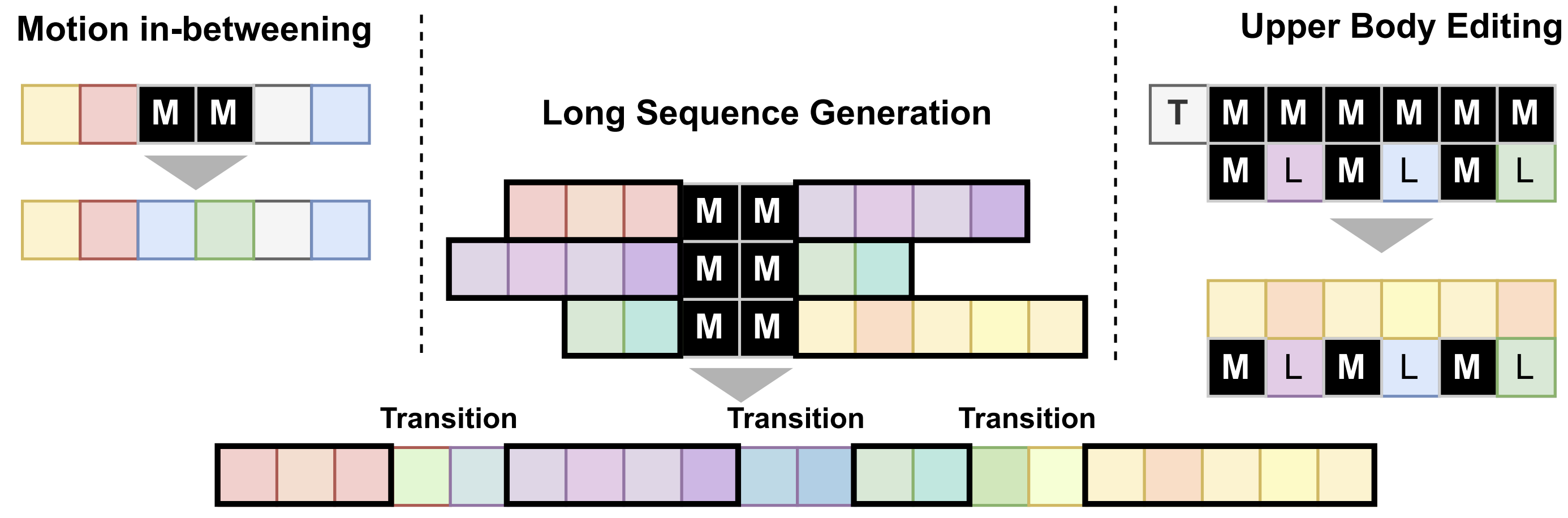
Motion Temporal Inpainting (Motion In-betweening):
Generating 50% motion in the middle based on the text “A person jumps forward” conditioned on first 25% and last 25% of motion of “a person walks forward, then is pushed to their left and then returns to walking in the line they were.”
MMM (our)
MDM
Generating 50% motion in the middle based on the text “a man throws a ball” conditioned on first 25% and last 25% of motion of “a person walks backward, turns around and walks backward the other way.”
MMM (our)
MDM
Upper body editing:
Generating upper body part based on the text “a man throws a ball” conditioned on lower body part of “a man rises from the ground, walks in a circle and sits back down on the ground.”
[Click play for normal speed]
MMM (our)
[Click play for normal speed]
MDM
More Results
Text to Motion:
MMM (our)
a person bouncing around while throwing jabs and upper cuts.
MMM (our)
a person start to dance with legs
MMM (our)
a person steps forward and leans over; they grab a cup with their left hand and empty it before putting it down and stepping back to their original position.
MMM (our)
walking forward and kicking foot.
Long Sequence Generation:
Generating long sequence motion by combining multiple motions as follow: 'a person walks forward then turn left.', 'a person crawling from left to right', 'a person dribbles a basketball then shoots it.', 'the person is walking in a counter counterclockwise circle.', 'a person is sitting in a chair, wobbles side to side, stands up, and then start walking.' Red frames indicate the generated short motion sequences. Blue frames indicate transition frames.
MMM (our)
Motion Completion:
MMM (our)
Completing first 50% motion based on the text “a person performs jumping jacks.” conditioned on last 50% of motion of “a person crawling from left to right”
MMM (our)
Completing last 50% motion based on the text “a person performs jumping jacks.” conditioned on first 50% of motion of “a person crawling from left to right”
Motion Temporal Outpainting:
MMM (our)
Generating first 25% and last 25% of motion of based on the text “A person sits down” conditioned on 50% motion in the middle of motion of “a person is running in place at a medium pace.”
MMM (our)
Generating first 25% and last 25% of motion of based on the text “person walks backward.” conditioned on 50% motion in the middle of motion of “a person walks forward in a straight line.”